
















ダウンロード TwitterWordCountReducer.java (1.0 KB)
ダウンロード JSONTweet.java (3.9 KB)
ダウンロード TwitterWordCountDriver.java (1.8 KB)
ダウンロード TwitterWordCountMapper.java (3.7 KB)
db tech showcaseはいかがでしたか?参加された方も、残念ながら参加できなかった方も、facebookで当日の熱気を感じてください!さて今回は、前回の最後で起動に失敗したHadoopクラスタを起動し、いよいよTwitterの分析に入ります。

今回のセッションで紹介されたデータベースがいくつあったかご存じですか?実に2桁にのぼる数のデータベースが紹介されていたのです。皆様は10以上のデータベース名をすぐに挙げることができますか?facebookのファンページでは当日の熱いセッション内容を見ることができます。一体いくつのデータベースが紹介されたのか、ぜひ数えてみてください!
パーミッションに注意!
さて、前回読んでいただいた方はどこに問題があったかお分かりになったでしょうか。ちなみに前回の記事ではCDH3のRPMパッケージインストールからスタートしているため、その前提となるJava SEのインストールには触れていませんでした。Javaが無くていきなり引っかかった方、ごめんなさい。
手順から抜けていたのは使用するディレクトリの作成と適切なパーミッションの設定です。基本的な部分ですが、だからこそ抜けやすい部分です。しかも、OSのファイルシステムに加えてHDFSにもパーミッションの概念があるため、両方を気にしなければなりません。では具体的に見てみましょう。
まずOS側のパーミッション設定です。これはわかりやすいですね。Hadoopが作業領域等で使用するディレクトリは、各サービスを起動するアカウント(hdfs, mapred)が読み書きできるようにパーミッションを設定する必要があります。指定したディレクトリがない場合はHadoopが自動的に作成しますので、ディレクトリ作成が可能であるように親ディレクトリのパーミッションを設定するのみでも問題ありません。
次にHDFSのパーミッション設定です。こちらは引っかかる方が多かったのではないでしょうか。というのも、実はHadoopの起動方法によってはエラーが出ないパターンも存在するのです。
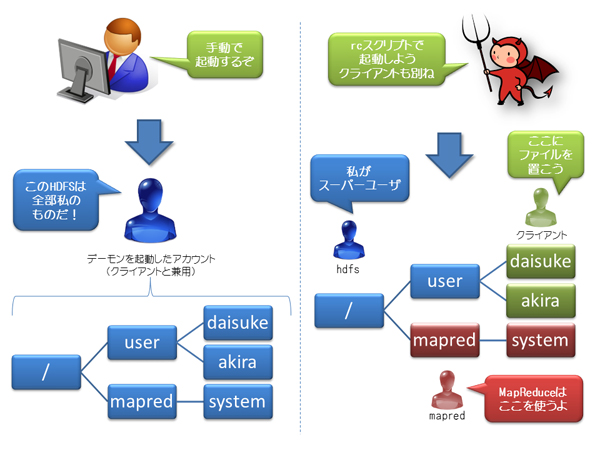
前回ご紹介した起動方法はrcスクリプトを使用したものです。この場合はこれまで説明した通りHDFSとMapReduceの各デーモンはそれぞれ専用のアカウント(hdfsとmapred)によって起動されます。また、この場合はMapReduceジョブを起動するクライアント用のアカウントも別途用意するのが一般的です。
これに対して、rcスクリプトを使用せずにデーモンを起動する方法もあります。Hadoopインストール先のbinディレクトリ(通常は/usr/lib/hadoop-0.20/bin)にstart-dfs.shなどの起動・停止用スクリプト類が配置されています。ここでその使用方法を細かく説明することはしませんが、マスタノードからsshのパスフレーズなし公開鍵認証でログイン可能なアカウントを各ノードで作成しておき、これらのスクリプトを実行することで、クラスタ内のデーモンの起動・停止を一気に行うことができます。この場合はHDFSとMapReduce、そしてクライアント用アカウントはすべて同一のものを用いるのが一般的です。
さて、HDFSではすべてのファイル・ディレクトリを操作できるスーパーユーザはNameNodeを起動したアカウントとなります。そのため、rcスクリプトを使用して起動した場合はhdfsアカウントがスーパーユーザとなります。よってMapReduceを起動するmapredアカウントや、別途用意したクライアント用のアカウントは自由にファイル・ディレクトリを作成することはできません。
一方でrcスクリプトを使用せずに起動した場合、一般的にはHDFS、MapReduce、クライアントすべて同じアカウントです。そのため、特にパーミッションを気にすることなくファイル・ディレクトリを作成することが可能です。
ここまでお読みいただければもうお分かりでしょう。JobTrackerが起動時にHDFS上にMapReduceのシステムファイル保存用ディレクトリを作成しようとしたところ、パーミッションがなく失敗したのが起動失敗の原因でした。筆者は今回のクラスタ作成以前、別のクラスタではrcスクリプトを使用せずに起動・停止を管理していました。そのため、この落とし穴に引っかかってしまったのです。
なお、MapReduceがHDFS上で使用するシステムファイル保存用ディレクトリはmapred.system.dirというプロパティで設定されます。今回はこれを設定していないため、デフォルトの「{hadoop.tmp.dirプロパティの設定値}/mapred/system」が作業用ディレクトリとして指定され、作成されます。hadoop.tmp.dirは/tmp/hadoopを設定していますので、今回は/tmpのパーミッションをすべてのユーザが読み書き実行を可能とすることで対応しました。ただあまり推奨できる運用ではないため、きちんとmapred.system.dirを設定することをお勧めします。
また、そもそもパーミッションの機能をすべて無効にすることもできます。dfs.permissionsというプロパティをfalseに設定すると、パーミッションを見なくなるためどのアカウントでも好きなところにファイル・ディレクトリを作成できます。
このほか、クライアントのホームディレクトリも作成しておきましょう。「/user/{アカウント名}」がホームディレクトリとなります。
HDFS上にディレクトリを作成するコマンドは「hadoop fs -mkdir」です。このほかhadoopコマンドにはHadoopを管理するための多数の機能があります。ここでは取り上げませんので、使用する際は各自確認しておきましょう。
ツイートをゲットだぜ!
Hadoopクラスタの構築も終わり、いよいよTwitterのデータを収集します。Twitterにはクライアントアプリケーションと連携するために多くのAPIが提供されています。今回はこのうち、 ストリーミングAPIのsampleというメソッドを使用します。これは全世界のツイートの約1%をリアルタイムに取得できるもので、ストリーミングの名の通り、HTTPの接続を閉じない限りデータを受信し続けるというものです。このメソッドはTwitter社から特別に許可を得る必要はなく、Twitterのアカウントを持っていれば誰でも使用することができます(2012年10月現在)。
今回はcurlコマンドを使用してツイートを取得し、それを1時間単位でファイルに書き出してHadoopクラスタへアップロードするシェルスクリプトを作成しました(リスト1)。このスクリプトをcronで1時間おきに実行します。
#!/bin/sh
. ~/.bash_profile
# アップロード先HDFSのパス
HADOOPDIR=/user/hadoop/DBOnline/twitterJson
# ツイートのダウンロードの際に一時的に使用するローカルのディレクトリ
LOCALDIR=/home/hadoop/DBOnline
# ファイル名
JSONFILE=${LOCALDIR}/`date +%Y%m%d-%H%M`.json
# Twitterのアカウント名とパスワードを設定
TWITTERUSERNAME=Twitterのアカウント名
TWITTERPASSWORD=Twitterのパスワード
# Twitter APIにアクセスしてツイートをダウンロードし続ける
curl -u${TWITTERUSERNAME}:${TWITTERPASSWORD} https://stream.twitter.com/1/statuses/sample.json > $JSONFILE &
# 約1時間(59分50秒)待ってcurlをkillする
PID=$!
sleep 3590
kill $PID
# HDFSにアップロードし、ローカルのファイルは削除
hadoop fs -put $JSONFILE $HADOOPDIR
rm -f $JSONFILE
リスト1: ツイートのダウンロード用スクリプト
なお、今回のスクリプトではTwitter APIの認証にBASIC認証を使用しています。しかし現在Twitterの認証にはOAuth認証が推奨されており、BASIC認証は非推奨です。このほかTwitter APIの仕様変更により記載のコードではツイートをダウンロードできなくなることも考えられます。また接続が切れた際の動作などエラー制御のコードはこのスクリプトには入っていません。実際に使用される際はこれらの点に注意してお試しください。
会員登録無料すると、続きをお読みいただけます
-
- Page 1
-
- Page 2
-
- Page 3
この記事は参考になりましたか?
- HadoopでTwitterを分析してみた連載記事一覧
-
- Mahout使って分析しちゃいました。
- みなさん、元気にMapReduceしてますか?
- Hadoopクラスタを起動、いよいよTwitterの分析へ
- この記事の著者
-

平間大輔(ヒラマダイスケ)
株式会社インサイトテクノロジー
ビッグデータ・ソリューション開発部 外資系ITアウトソーシング会社を経て2011年にインサイトテクノロジー入社。
Oracle大好き、SQLのコーディング大好き人間だったが、気づけばSSD, InfiniBand, Hadoopといった旬のハー...※プロフィールは、執筆時点、または直近の記事の寄稿時点での内容です

この記事は参考になりましたか?
この記事をシェア