

















データ分析とコストのジレンマに終止符──「諦めたログ」も活かすSplunk×Amazon S3活用術
「SplunkユーザーにAWSの新しい選択肢を」検証結果から見えた本当に価値のあるデータパイプライン

企業でクラウドやAIの活用が進むにつれ、それを監視し、リスクを回避するためのログデータも爆発的に増加している。ログデータの増加に比例してそれを管理するライセンス費用も増大することで、コストの負担に悩むIT運用者も少なくない。そこで注目されているのが、コストパフォーマンスに優れた「オブジェクトストレージ」を活用した分析手法だ。2025年7月17日に開催されたSplunk主催カンファレンス「Splunk Experience Day Tokyo 2025」に登壇したクラスメソッドのソリューションアーキテクト 酒井剛氏は、「Amazon Simple Storage Service(以下、Amazon S3)」とSplunkの連携によって、膨大なログ分析をリーズナブルに実現する「Splunk Federated Search for Amazon S3」の実装方法を紹介した。
今まで諦めていた“低頻度”なデータ分析が可能に?
生成AIや自律型システムの普及にともない、マシンデータを適切に監視し、リスクに迅速に対応できる体制を整備することの重要性はますます高まっている。そのためには、サーバーログ、アプリケーションイベント、ネットワークトラフィック、センサー情報などの膨大なマシンデータをリアルタイムに収集・分析し、異常検知や最適化につなげるデータプラットフォームが肝となる。
その一つの選択肢として多くの企業で導入が進んでいるのがSplunkだ。企業のITシステムやアプリケーションから生成される膨大なマシンデータを収集・分析し、システム運用の最適化やアプリケーションの可視化、業務の意思決定支援など、幅広い用途で活用できるデータプラットフォームとしての機能を備えている。クラウド版のSplunk Cloudでは、リアルタイムのモニタリングから高度な相関分析まで対応可能な検索・分析機能を備えており、多様な業務領域での洞察の獲得と課題解決を支援する。
しかし、その優れた機能と引き換えに、利用料金は取り込むデータ量に応じて課金される仕組みとなっており、データ量が増えれば増えるほどライセンス費用も増大する構造を持つ。このコスト負担のイメージが、多くの企業にとってSplunkの活用拡大の大きな障壁となっていた。
酒井氏はまず、現在多くの企業が直面している課題を明確に示した。「クラウドの有効活用やDXが進むにつれて、管理すべきログの量は増加の一途を辿る。取り込むデータ量に応じて加算される費用が、全体のライセンス費用の大部分を占めている企業は多い」と指摘し、データ量の増加とコスト増大の関係性を説明した。

この課題に対する解決策として酒井氏は「Splunk Federated Search for S3(以下、FSS3)」の活用を提案する。FSS3は、Splunk Cloudにデータを直接取り込まずにダイレクトクエリできる機能で、AWSが提供するクラウドストレージサービス「Amazon S3」の構造とAPIに特化して設計されている。これを活用することで、従来のデータ処理フローを根本的に変革できるとした。酒井氏は、実際にFSS3を活用する場合のシステムのアーキテクチャとして、Amazon S3、AWS GlueとSplunk Cloudを連携させ、アクセスする頻度の少ないデータを安価なAmazon S3に保存しながら、アクセスが必要な時にはSplunkの高度な分析機能でアクセスできる仕組みを提案する。
また、具体的なFSS3の活用場面は、5つのユースケースによって紹介された。まず1つ目に、頻繁には利用しないものの、万が一のセキュリティ調査時にアクセスが必要となるような“アクセス頻度の少ない”ケース。2つ目に、セキュリティインシデント発生時における侵入経路の調査時に用いられるケースが考えられる。3つ目には、レポートを作成する際に古いデータを活用するような“過去データの統計”ケースが該当する。4つ目に、法規制を遵守するために一定期間データを長期保管する必要があるといった観点から、コンプライアンス対応での活用も期待される。そして最後に、クエリ実行を一元化することで、操作の簡便さやスピード、アクセス性を高め、組織全体の分析効率を向上させる「ログ分析の中央化」にも効果があると説明した。
酒井氏は「これらのユースケースはすべて、取り込まなければいけないデータ量に対して実施頻度が低かったり、従来はコストや手間の問題から活用がためらわれていたりした領域だ」と述べ、FSS3によってより柔軟なデータ分析が可能になることを示した。

コストを削減して運用も楽にする新アーキテクチャとは
では、FSS3を活用する際のシステムアーキテクチャはどのように構成されるのか。酒井氏は、FSS3のデータパイプライン構築について、3つの主要コンポーネントで構成されるアーキテクチャを解説した。
第一のコンポーネントがSplunkのIngest Actionsだ。これはデータを取り込む前に様々な変換処理を行える機能で、不要なデータのフィルタリングや機密情報のマスキングといった処理を自動で行うことができる。Ingest Actionsでフィルタリング・転送されたデータはSplunkのライセンスカウント対象外となるため、Splunkのコストを大幅に削減可能だ。
第二のコンポーネントがAmazon S3。フラットな構造を持つオブジェクトストレージとして、大量のログデータを安価に保存する役割を担う。
そして第三のコンポーネントがAWS GlueのData Catalogである。Amazon S3に保存されたデータの構造を定義・管理するメタデータリポジトリとして機能し、様々なデータソースのメタデータ(スキーマ、場所など)を一元的に保存・管理することで、Splunk Cloudからの効率的なデータアクセスを可能にするものだ。
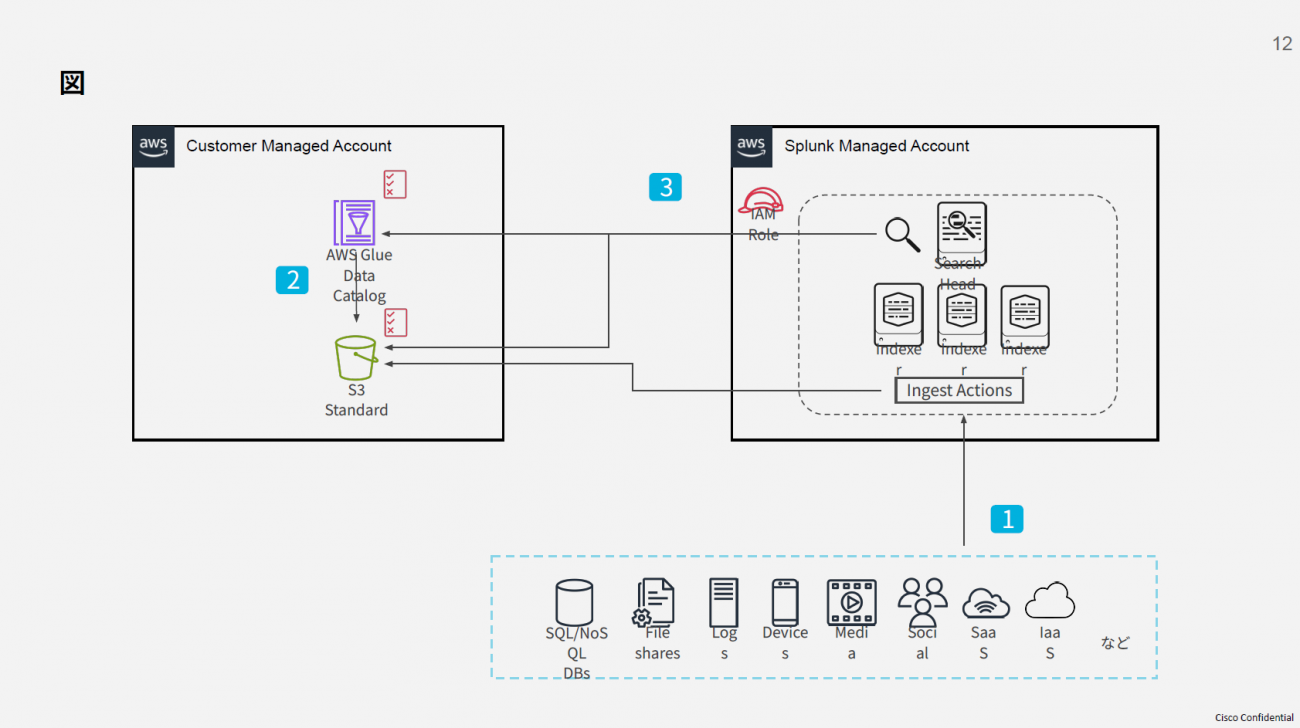
FSS3のデータパイプライン図
[クリックすると拡大します]
ただし、Amazon S3にあるデータをSplunk Cloudで検索する際は、スキャンしたデータ量に応じてSplunk CloudのオプションライセンスであるDSU(Data Scan Unit)を消費するため、スキャン対象となるデータ量を最適化することが重要となる。そこで活用されるのが、Ingest Actionsによる「パーティショニング」だ。ログのタイムスタンプを読み取り、自動的に「YYYY/MM/DD」などのプレフィックス(Amazon S3内でデータを識別するためのキー情報)を付けてデータを転送することで、検索時のスキャン範囲を絞り込める機能である。
酒井氏は、Ingest Actionsによるプレフィックスを用いたパーティショニングにより「コスト・検索の両方でパフォーマンスが向上する」と説明し、「運用面までよく考えられていて非常に優れている」と高く評価した。
Amazon S3に日々蓄積されるログデータを効率的に検索するためには、パーティショニングをいかにうまく活用するかといった戦略が重要となるが、新しいデータが追加されるたびに管理者が手作業でパーティション設定を行っていては手間がかかる。また、長期運用により蓄積されたパーティション数が増えると、検索性能が低下するという問題も生じる。膨大なパーティション数によってクエリ時間が大幅に伸びる現象が発生し、システム全体のレスポンスが悪化してしまうのだ。
これらの運用課題を解決する方法として、酒井氏はAmazon AthenaのPartition Projection機能を紹介した。これは、Amazon S3上のパーティション構造をテーブルの設定から自動で推論し、事前のパーティション登録作業を不要にする技術。これにより、日々の運用作業が軽減され、クエリの高速化にもつながる。
Partition Projection機能の実装例として、同氏はWebサーバーのアクセスログを取り上げた。アクセスログは通常、1行の長文テキストとして出力されるが、Amazon Athenaでテーブルを定義し、各ログ項目(IPアドレス、タイムスタンプ、リクエスト内容など)を列として設定することで、SQLでの検索が可能になる。ログの形式に応じて、Grokなどの正規表現ベースのパーサーを活用すれば、構造化されていないログも扱いやすくなる。
定義されたテーブルはAWS Glue Data Catalogに保存され、Partition Projectionの設定により、日付などのルールに従ったパーティションの自動管理が実現される。これにより、日々のパーティション追加や管理が不要となり、運用コストと手間を大幅に削減できるとした。
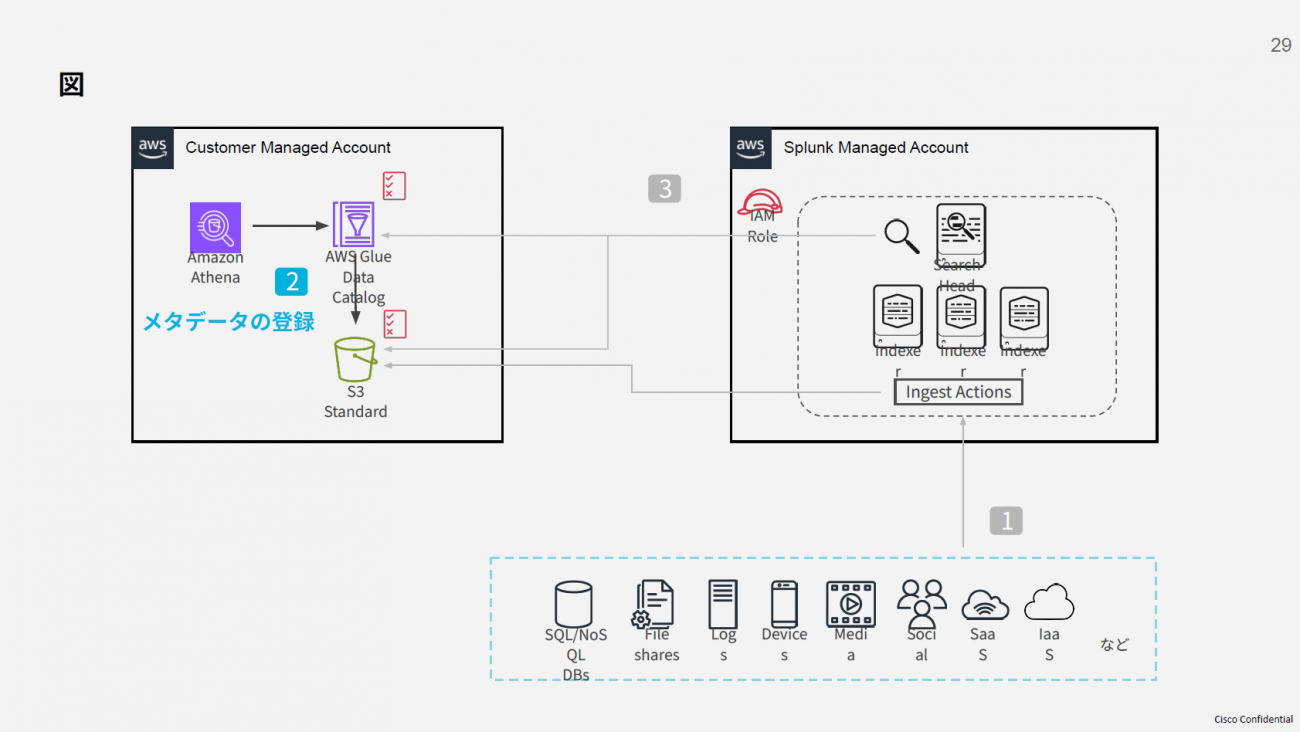
[クリックすると拡大します]
AWS側の設定ができたら、次にSplunk Cloud側でアクセス設定を行う。Splunkには、複数のインスタンスや外部のデータソースを横断して検索できる「Federated Search」という機能が備わっており、Splunkが外部データソースと連携・検索する際の“接続先”を定義した「Federated Providers」と呼ばれる構成要素を持つ。ここから、Splunk CloudがAWS Glue Data Catalogを参照し、Amazon S3にアクセスするための権限ポリシーを設定する。これによりクロスアカウントでのデータアクセスが可能になる。
また「Federated Index」の設定も必要になる。ここでは、AWS Glue Data Catalogで定義された時間フィールドをSplunk Cloudの内部時間にマッピングし、検索時にパーティションフィールドを適切に識別できるよう設定する。これにより、Splunk CloudからAmazon S3内のデータを効率的に検索できるようになる。
実際のテスト結果から見えたFSS3の価値
酒井氏は、今回紹介した仕組みのパフォーマンスをテストした結果を示した。3つの異なるAmazon S3パーティションでのテストを実施し、データ量と検索時間の関係を定量的に測定した結果、1.7MBのデータでは2.352秒、475MBでは29.038秒、3.4GBでは51.904秒という結果を得たという。

この結果について酒井氏は「検索時間が30秒を超えると調査などには使いづらい」と率直に評価する。そこで、ファイル数が増えると検索時間も延びる傾向を踏まえ、データ形式の最適化によるコンパクション戦略の実証結果も紹介した。
コンパクションとは、複数の小さなファイルを一つにまとめると同時に、データ形式をより効率的なものに変換する処理だ。酒井氏が紹介したテストでは、26,123個のオブジェクトに分散していた2.5GBのデータ(検索時間40.118秒)に対して、複数ファイルの統合とJSON形式からParquet形式への変換が実施された。
Parquet形式は列指向ストレージフォーマットと呼ばれる効率的なデータ形式で、行指向のJSONと比較して分析処理に最適化されている。この変換により、データは1オブジェクト・1.6MBまでコンパクト化され、検索時間も3.682秒まで劇的に短縮された。
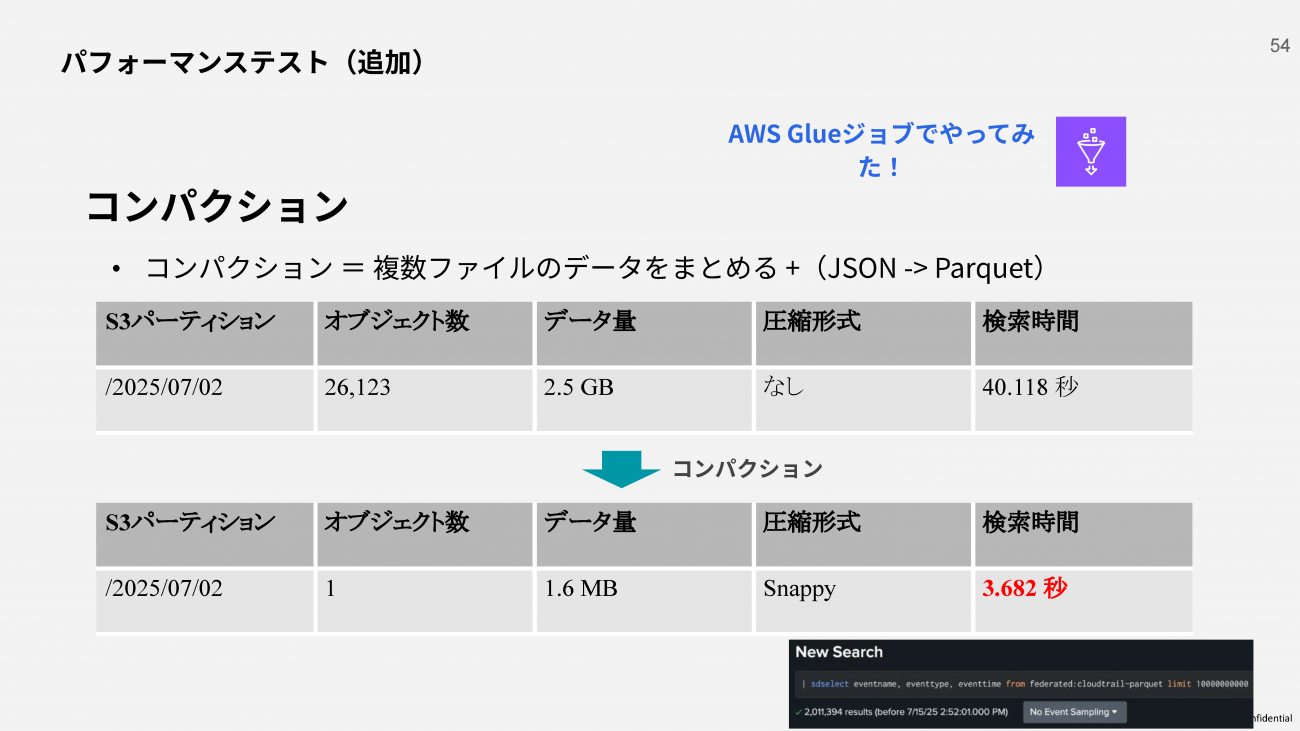
[クリックすると拡大します]
また同氏は、コスト面での優位性について、毎日3.4GBのデータを30日間保存したケースの料金試算を例にとって説明した。この場合、Amazon S3の月額費用が2.55ドル、PUT API費用が0.013ドル、AWS Glue Data Catalog費用は無料範囲内となる結果を示す。「AWSの料金は従量課金となるため、あくまで参考費用だ」と前置きしつつ、Splunk Cloudに直接取り込む場合と比較して大幅なコスト削減効果が期待できるとした。
今回の検証を踏まえ、酒井氏は今後のSplunk機能拡張への期待を語った。「Ingest Actionsがコンパクション機能に対応すれば、大幅な改善が期待できる」と具体的な機能改善を要望し、現在は手動で行っているデータ最適化処理の自動化が実現すれば、さらなる効率向上が期待できると展望を示した。
「魅力的なのに知られていない」データ活用の選択肢を広げるために
講演を通して酒井氏が特に強調したのは、FSS3の潜在的価値と実装における課題のギャップだ。「SplunkユーザーがFSS3を使えば、大幅なコスト削減を実現できる。多くのユーザーにとって魅力的なソリューションに映ると思われるが、『Splunkのことは知っていてもAWSに関する知識が足りないために、実装方法が分からない』という相談が非常に多い」と話す。このような背景から、AWSソリューションをメインで扱っているクラスメソッドには相談の声が多く寄せられているという。

酒井氏がFSS3の活用を提案する背景には、AWSとSplunkそれぞれの強みを最大化するための戦略がある。「データの検索や分析を行うにあたってはSplunkの方が使いやすい」ことを示した上で、「AWSを使ったほうが効率的な部分では上手に活用する」という融合型のアプローチを採る重要性を強調する。
さらに、クラスメソッドが提供するAWSプライベートオファリングについても触れ、AWSの料金とSplunkの料金を合算して支払いができると紹介した。
最後に、Splunkの“オンプレミス環境で利用できるサービス”というイメージがまだ根強いことにも触れ、「Splunk Cloudはデータの取り込み量で課金されるため、コストが高いという認識を持つ人も少なくない。そのような人たちには特に、今回紹介したような選択肢もあることを知っていただきたい。そして、今まではコストを理由に諦めていたデータの活用にも取り組むことで、データ活用の幅を広げていっていただければうれしい」とコメントした。
この記事は参考になりましたか?
提供:Splunk Services Japan 合同会社
【AD】本記事の内容は記事掲載開始時点のものです 企画・制作 株式会社翔泳社
この記事は参考になりましたか?
この記事をシェア