

















日本テラデータは2025年7月30日、会見を開催し、同社のAI戦略の最新動向を発表した。代表取締役社長の大澤毅氏、執行役員コンサルティング本部本部長の小峰誠司氏、技術営業本部AI技術営業室室長の八田秦史氏が、7月31日にリリースするオンプレミス完結型AI基盤「Teradata AI Factory」を中心に、企業のAIドリブン経営を支援する取り組みについて説明した。
「真のAIドリブン経営」実現に向けた3つの取り組み

大澤社長は冒頭で「日本テラデータのイメージを完全に変えたい」という強い決意を表明し、昨年11月に発表したAIに特化した事業戦略の進捗を報告した。同社は「データ×AIエージェントの最新ソリューションで、日本企業の『真のAIドリブン経営』を実現する」という大きなミッションを掲げており、この目標を達成するため年内に各業界でAIドリブンを牽引する「キャプテン20社」の確立を約束している。
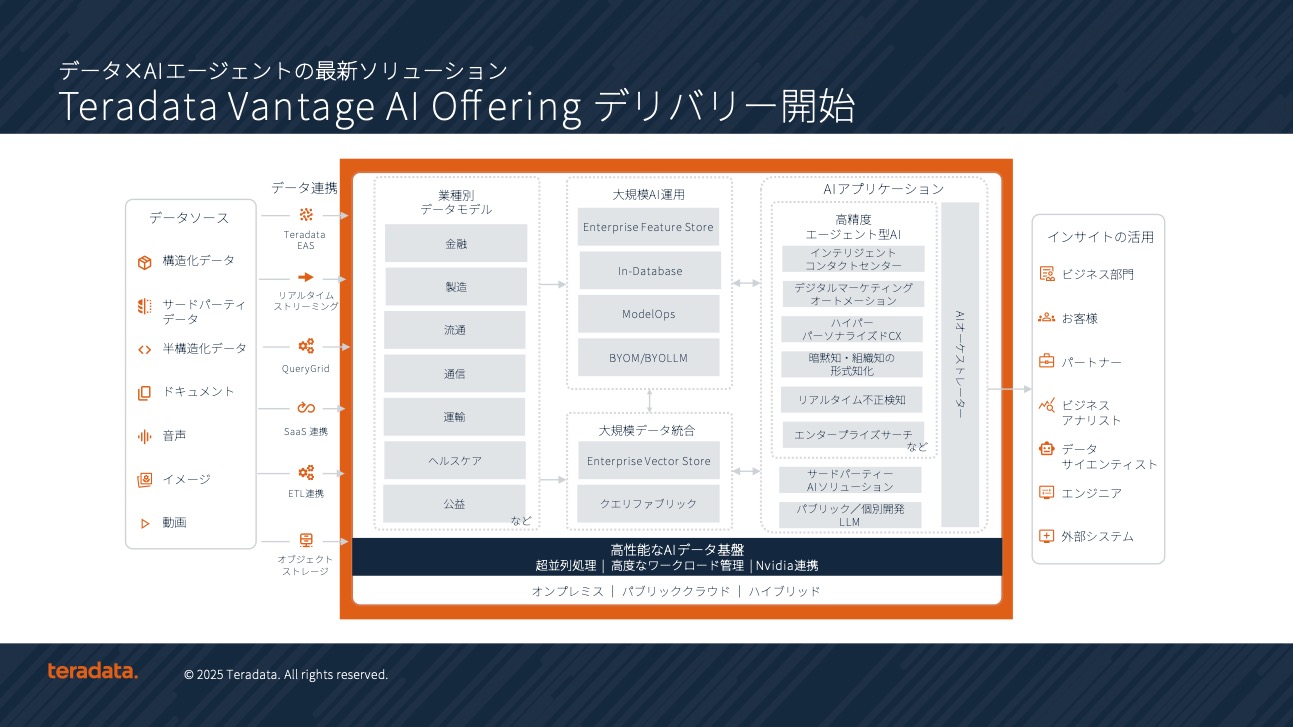
このキャプテン20社確立に向けた取り組みとして、大澤氏は3つの柱を示した。第1の「協走」では、Teradata Vantageという統合データ基盤上にAIユースケースをあらかじめプリセットしたAIプリセットモデルの実装により、顧客が迅速にAIを本番運用に移行できる環境を提供する。第2の「強壮」では、クラウドとオンプレミス両方に対応するハイブリッドデータプラットフォームを提供し、昨今重要性が増しているオンプレミス環境でのデータ活用ニーズに応える。第3の「共創」では、AI戦略アドバイザリーサービスを通じて、企業の戦略立案段階から支援を行う。
大澤氏は企業からの要望として3つの課題を整理している。「2年前から生成AIを使ったプロジェクトを走らせていたが、会社規模やユニット規模でAIのユースケースを広く実現するためには、生成AIだけでは人間の代わりにはなれない。実業務そのもの、サービスそのものをAIによって自動化、品質向上を図るエージェント型AIを求められている」と述べ、生成AI中心のPoCから脱却し、すぐに成果を創出できるシステムの必要性を強調した。また、製造業では新規開発データや実験データなど「クラウドに持っていけない重要なデータや機密データ」があり、オンプレミスでデータ基盤からエージェント型AI基盤、アプリケーションまでを提供できるベンダーが不足していると指摘した。
ソブリンAIによるデータ主権の確立
これらの課題に対する同社の回答が、NVIDIAとの共同開発により実現したTeradata AI Factoryである。この製品の最大の特徴は、企業がクラウドに依存することなく、自社内でAIを運用できる「ソブリンAI」を実現することにある。

八田秦史氏は製品の特徴について、「クラウド依存を排除して、オンプレミス完結型AI基盤によるソブリンAIを実現し、データ主権やコンプライアンス要件への対応が可能です」と説明した。従来のAI活用では海外のクラウドサービスプロバイダーに依存せざるを得ない状況が多かったが、政権の変化や法制度の影響を受けにくいオンプレミス環境でのAI実行により、企業はデータの主権を取り戻すことができる。

八田氏は、エージェント型AIの時代における同社の強みについて「我々が40年培ってきたデータの超並列処理と業界最高のインテリジェントワークロード管理を備えるTeradata Vantageの重要性が増してきている」と強調した。「AIエージェントの時代になるとデータの検索やクエリー処理が数10から数100倍に増加し、マルチエージェントの複数のエージェントがチームでタスクを同時並行的に行っていくことで、膨大なデータ検索が走る。これをクラウドだけで実装してもかなりコストバーストを起こしてしまう」と述べ、同社の技術的優位性を説明した。

同製品は、データベースエンジンの最新バージョン20を搭載し、NVIDIA AI Enterpriseと密に連携して動作する。これにより、構造化データと非構造化データの両方を統合したベクトルストアデータベースとして機能し、生成AIやエージェント型AIのサービス基盤として活用できる。また、AI Workbenchという開発環境も提供され、業界別のユースケースを参考にカスタマイズしたエージェント型AIの開発が可能である。
エージェント型AIの実現とコスト最適化
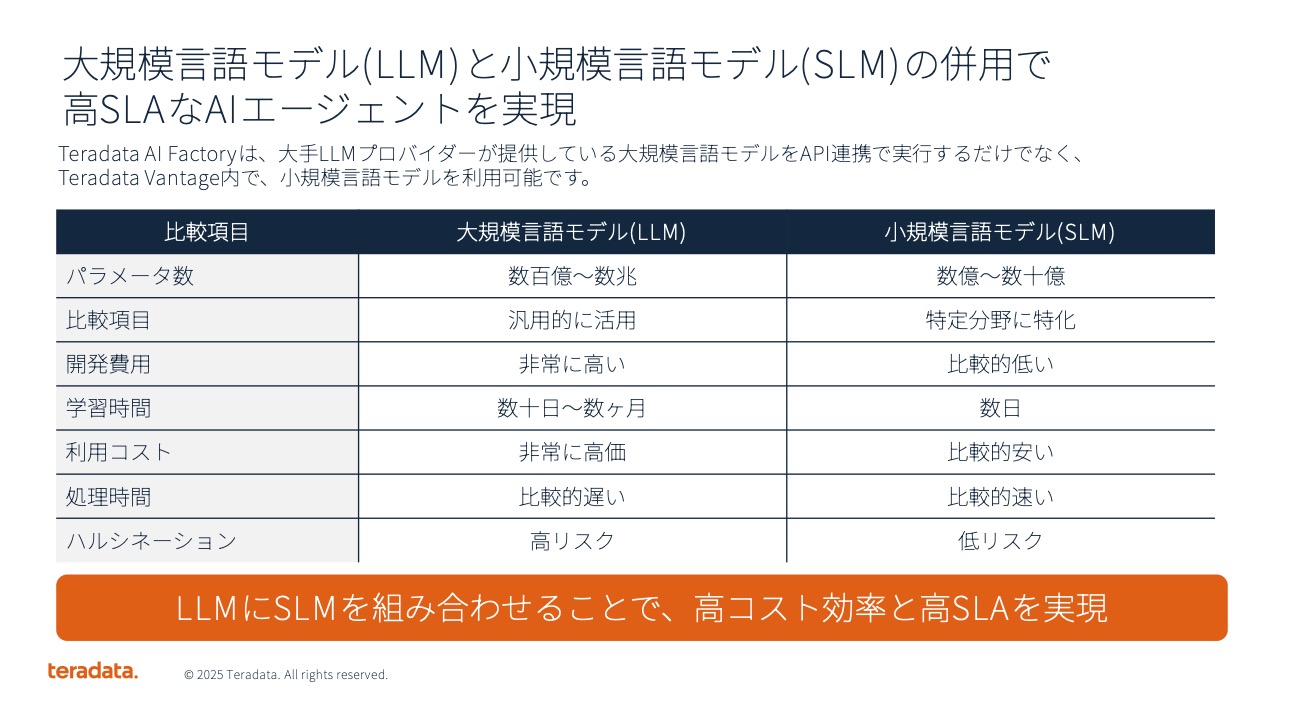
Teradata AI Factoryの重要な特徴として、大規模言語モデルと小規模言語モデルを組み合わせて使用できる点が挙げられる。大規模言語モデルは汎用性が高い反面、コストが高く、レスポンスタイムが遅くなる傾向がある。一方、小規模言語モデルは業務に特化することで、コスト効率とSLA(サービスレベル)の向上を実現できる。
八田氏は「エージェント型AIを実現していくということを考えた場合、マルチエージェントで構成し、それらがオーケストレーションしないといけないする必要がある。大規模言語モデル(LLM)と小規模言語モデル(SLM)を組み合わせて、最適なSLAとコスト効率を実現することが重要になる」と強調した。
八田氏は、同社のソリューションについて「マルチエージェントで複数の専門エージェントをオーケストレーションさせて、複雑な業務を実行させることが可能で、そのタスクを高精度に行うことが既に実現できている」と説明し、SDKによるきめ細かいガードレール制御により、金融機関などの厳しい安全基準にも適合できる構造になっていることを強調した。
この製品は基本的にレンタル形式で提供され、コンサルティングサービスや保守サービスとセットでの提供も可能である。オンプレミス環境では従量課金によるコストバーストの心配がなく、予測可能なコスト管理が実現できる点も企業にとって大きなメリットとなる。
現在、通信キャリアや大手SIerが展開するソブリンクラウド環境への導入、保険業界の引き受け自動化、製造業での暗黙知の形式化、コールセンターでの音声情報活用、医療・ヘルスケア分野でのゲノム情報やカルテ情報の処理、防衛分野での機密情報処理など、幅広い分野での引き合いを受けているという。
AIコンサルティング体制の強化
同社は、エージェント型AIユースケースを広く顧客に提供するため、230名のコンサルティング部隊の中に100名のAIコンサルティングチームを新設した。このチームは「AIインテグレーション&デリバリーチーム」として、企画段階からエージェント型AIアプリケーションの稼働まで、短期間でのサポートを提供する。
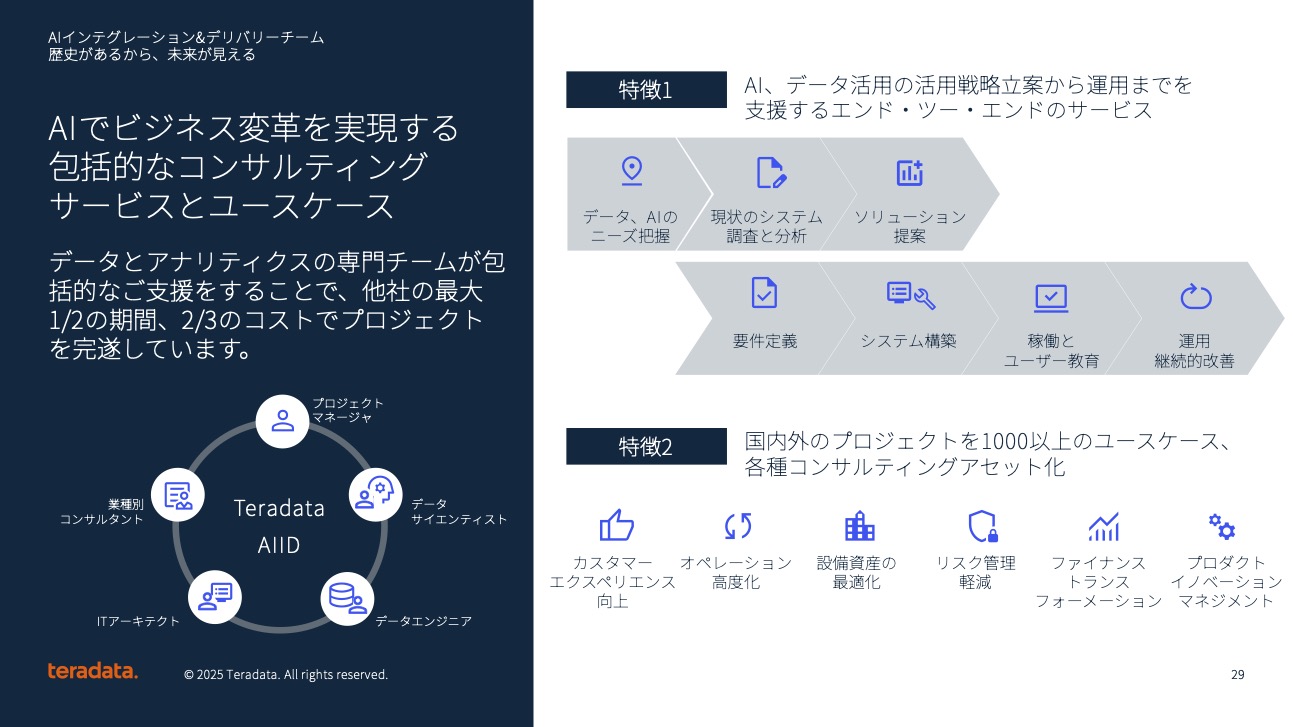
執行役員 コンサルティング本部 本部長 小峰誠司氏は、このチームの特徴について「日本からの発案であり発信です。日本独自で完結できる、そういったトップタレントを集めたAIのデリバリーを遂行するチーム」と説明し、40年にわたる豊富なユースケースの蓄積と業界別データモデル(IDM)を活用した一気通貫型のサービス展開を行うとした。

大澤氏は「真のAIドリブン経営を目指す企業の皆様の企画段階からのご支援や、短期間でのエージェント型AIアプリケーションの稼働等々をお約束することが可能となった」と述べ、同社の総合的な支援体制の確立を強調した。同社は、生成AIだけでは実現できない実業務レベルでのAI活用、POCの沼からの脱却、機密データのオンプレミス処理という3つの企業課題に対し、統合的なソリューションで応えていく方針である。
この記事は参考になりましたか?
- この記事の著者
-

京部康男 (編集部)(キョウベヤスオ)
ライター兼エディター。翔泳社EnterpriseZine/AIdiverには業務委託として関わる。翔泳社在籍時には各種イベントの立ち上げやメディア、書籍、イベントに関わってきた。現在はフリーランスとして、エンタープライズIT、行政情報IT関連、企業のWeb記事作成、企業出版支援などを行う。Mail ...
※プロフィールは、執筆時点、または直近の記事の寄稿時点での内容です

この記事は参考になりましたか?
この記事をシェア