

















こんにちは。日本マイクロソフトの北川です。NIKU には「ストレスを減らし、心の安定を保つ」作用のあるセロトニンを生成するうえで重要なトリプトファンという必須アミノ酸とビタミン B6 が含まれています。結果、お肉を食べると幸せを感じるのだといわれています。調理されて供される肉料理をパッケージ アプリケーションとすれば、自分で好きなように焼き、好みの味付けで食べられる焼肉はまさに経験とスキルの塊であるカスタム アプリケーションといえるでしょう。これまでに蓄積したスキルを存分に生かして、美味しいお肉を焼き上げることができれば、より幸せを感じることができるかと思います。実はこの原稿は NIKU エネルギーで執筆しています。
第5回では教師あり学習を行うためのデータセットを Azure ML 上に登録しました。第6回ではこのデータを使用して極鶏.Bar の売上予測を行うモデルの作成を行います。
データ件数は機械学習で利用するほど多くありませんが、どれくらいの精度のモデルができるでしょうか。少し不安ではあります。
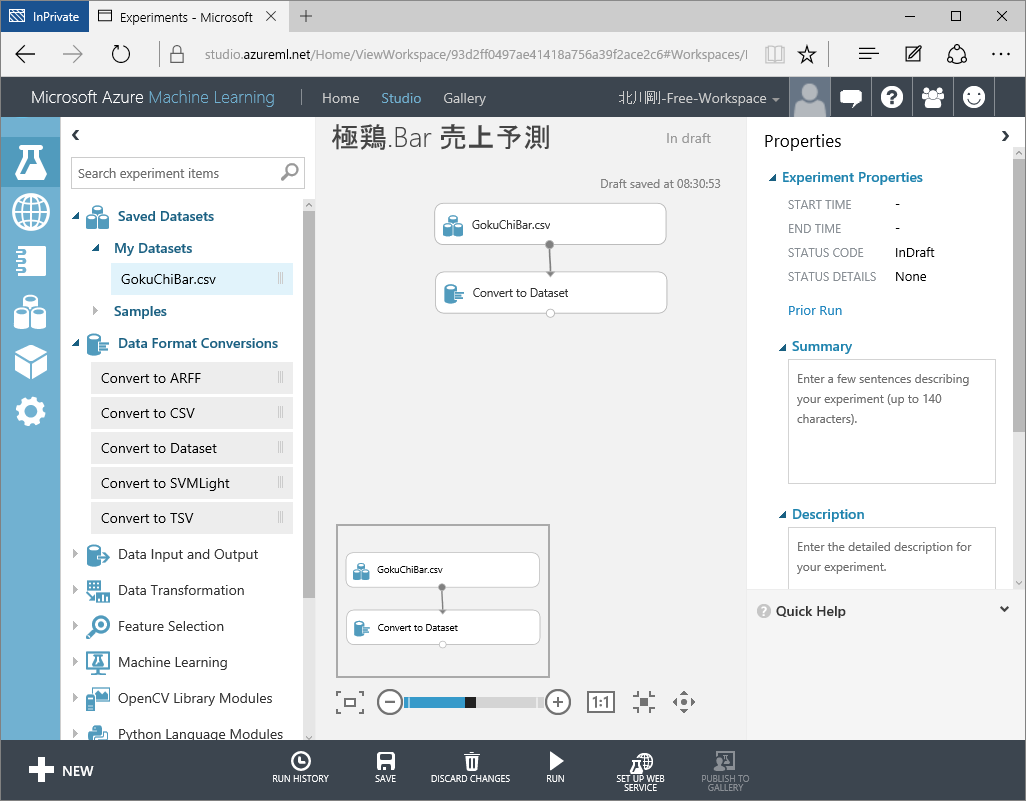
上記では、保存されたデータセット(CSV)を、Azure ML で使用する内部データセットに明示的な変換を行うため「Convert to Dataset」モジュールを追加しています。データに対して何らかの操作を行う場合、データは Azure ML によってネイティブのデータセットに暗黙的に変換されますが、欠損値を特定の文字に置き換えたり、特定の文字列を置換したり、スパースデータの欠損値の処理方法を指定することで、より安定して分析できるデータセットを生成することができます。ここでは欠損値(Missing Value)が「?」に置換されたデータセットを生成しています。
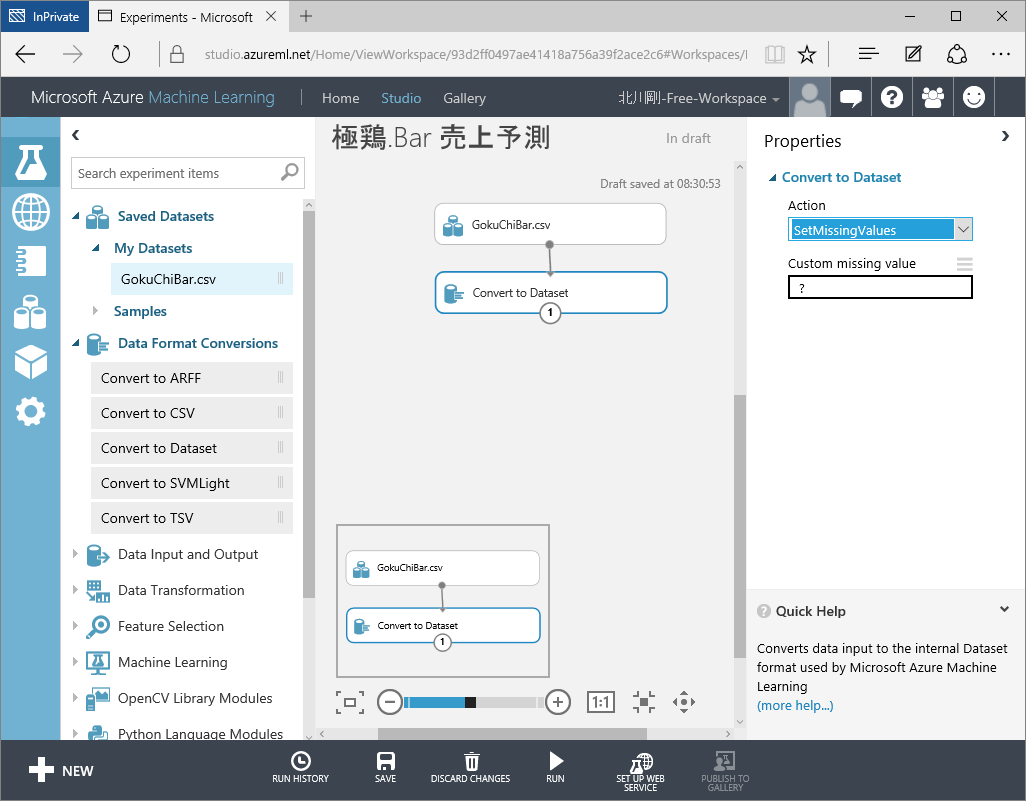
データセットを生成するために、画面下のメニューから「RUN」をクリックします。
一度システム上で Queue に入り、その後実行が行われます。実行が完了すると、Convert Dataset のモジュールに緑のチェックマークがつきます。
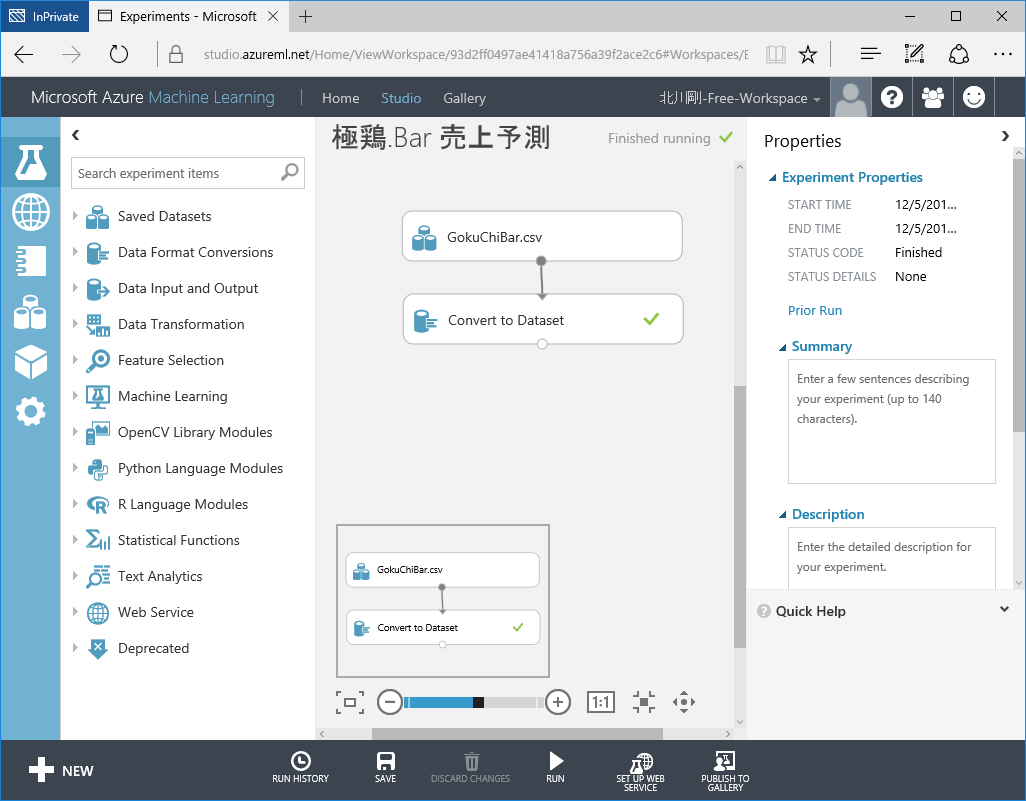
これで、明示的にデータセットを作成することができました。
ここで「Convert Dataset」の出力ポートを右クリックすると、データを参照したり、保存したりするためのコンテキスト メニューが表示されますので、データを参照するための Visualize をクリックします。
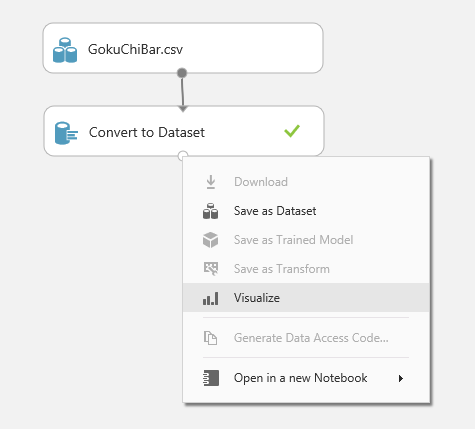
こうすることで、データセットの中身を参照することができます。
なお、このデータはすべてのデータが表示されるわけではありません。
表示されたデータの特定の列を選択すると、画面右に Statustics と Visualizations が表示されます。
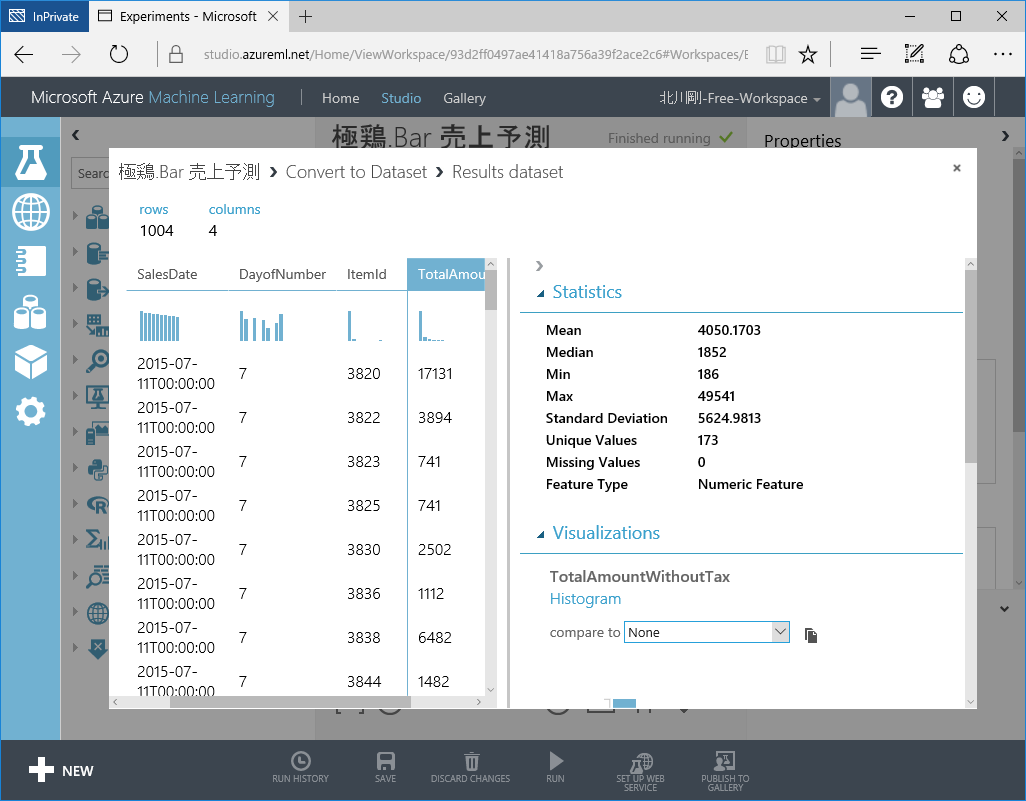
上記では TotalAmountWithoutTax というその日の特定の ItemId の売上合計(税抜)を選択しています。
画面右の Statustics を参照すると、平均値(Mean)や中央値(Median)、最小値(Min)、最大値(Max)、標準偏差(Standard Deviation)、一意の値の数(Unique Values)、欠損値の数(Missing Values)、Feature Type が表示されます。
数値型ではない、SalesDate を選択すると、Mean や Median などのフィールドは NaN(Not a Number)が表示されます。もちろん、Feature Type としては DateTime となります。
では、実際に売り上げ予測を行うために、モデル構築を進めていきたいと思います。
今回は売り上げ予測を行いますが、その際どのアルゴリズムを利用すべきなのかの選択が一番悩ましいかと思います。そこで、Azure ML では「機械学習アルゴリズム チート シート」を提供しています。(引用元)
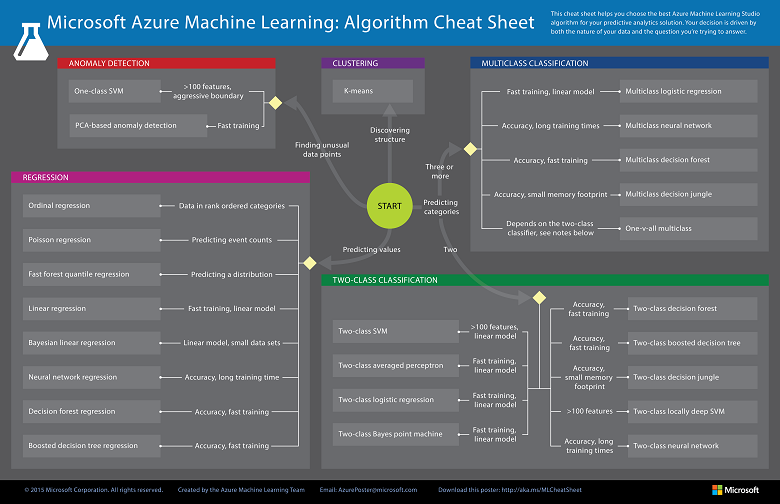
今回は「売り上げ予測」ですので「Predicting Value」の中から選択します。
線形回帰を行う Boosted Decition Tree Regression を選択してみることにしましょう。
まず、保存したデータを学習用のデータと検証用のデータに分割する必要があります。そのため左側のパレットから Data Transformation > Sample and Split を展開し、Split Data モジュールをキャンバスに配置し、Convert Dataset の出力ポートと Split Data の入力ポートとを接続します。
Split Data モジュールを選択し、右側のプロパティでデータを分割する比率を入力します。デフォルトは出力ポート1と出力ポート2に半数ずつ出力するため 0.5 が入力されていますが、今回は 80% のデータを利用して学習を行い、20% のデータを利用してテストを行うため、0.8 と入力し、データ分割をランダムに行うため、Randomized Split にチェックを入れます。
会員登録無料すると、続きをお読みいただけます
-
- Page 1
-
-
- Page 2
-
-
- Page 3
-
この記事は参考になりましたか?
- マイクロソフト北川剛のイチからはじめるPower BI入門講座連載記事一覧
-
- そもそもなぜPower BIなのか
- Power BI の機能拡張を使ってみよう
- 売上予測を行うモデルを作成してみよう(モデル作成編)
- この記事の著者
-

北川剛(キタガワツヨシ)
日本マイクロソフト株式会社日本マイクロソフトで Azure を含むサーバー製品を担当するプロダクトマネージャー。 大学時代にインターネットの洗礼を受け、研究室でデータベースを利用したウェブシステムを構築するというきっかけを得たことから、データベースの道に進むことに。現在はデータベースだけではなく、ク...
※プロフィールは、執筆時点、または直近の記事の寄稿時点での内容です

この記事は参考になりましたか?
この記事をシェア