
















今まで5回の連載を通してSAP HANAの主にアーキテクチャ観点からの特徴を解説してきましたが、最終回はOracle技術者から見た「SAP HANAの凄い点」についてまとめてみたいと思います。
あくまでもOracle技術者として感じた「隣の芝生は青い」的な所見ですので、SAP HANAを実業務でお使いの方は若干異なる印象を持たれているかもしれません。その点ご承知ください。また、内容についてはSAP社員の監修を受けていますが、Oracle技術者にイメージしやすいものとするためSAP社の説明と異なる表現となる可能性もありますのでご了承ください。
HANAカラムストアがもたらす副次効果
カラムストアはローストアに比べ、ベクトル(配列)の要素を膨大な繰り返し計算で処理するベクトル処理向けであることや、圧縮によるコンパクト化がメリットして取り上げられることが多いのですが、アーキテクチャ観点から見ると多くの興味深い副次効果があります。
データの断片化が発生しない構造
連載第2回で簡単に紹介しましたが、Oracleデータベースは表領域単位で固定サイズのデータブロック(以下ブロック)にデータを格納しています。

固定長のブロックに可変長データを格納したり、更新・削除するといろいろな問題が発生します。例えば、ブロック内の空き領域を超えてデータを更新しようとする際、1レコードを同じブロックに格納できない場合は、元のブロックにポインタを残して別のブロックにデータを移行する「行移行」が発生します。
また、初めから1レコードの長さがブロック長を超える場合は、2つ以上のブロックにまたがってデータが格納される「行連鎖」が発生します(カラム数が255を超える場合にも行連鎖が発生し、1レコードが別々のブロックにまたがることもあります)。
あるいは、DELETE文でデータを行単位に削除することでブロック内に再利用可能な空き領域が発生しますが、以降のINSERT文で格納されるべきレコード長が空き領域を超えている場合は、使用されない小さい空き領域の断片が虫食い状態的に生じることになります(セグメントレベルの断片化)。
さらに、テーブル等をDROPした際にも表領域の中に空きが発生するので、同様に小さい空き領域の断片が多数発生する可能性もあります(表領域レベルの断片化)。
第5回でも触れましたがブロックはディスクに永続化される単位でもあるため、行移行・行連鎖あるいは空き領域の断片化等は永続化により固定されます。
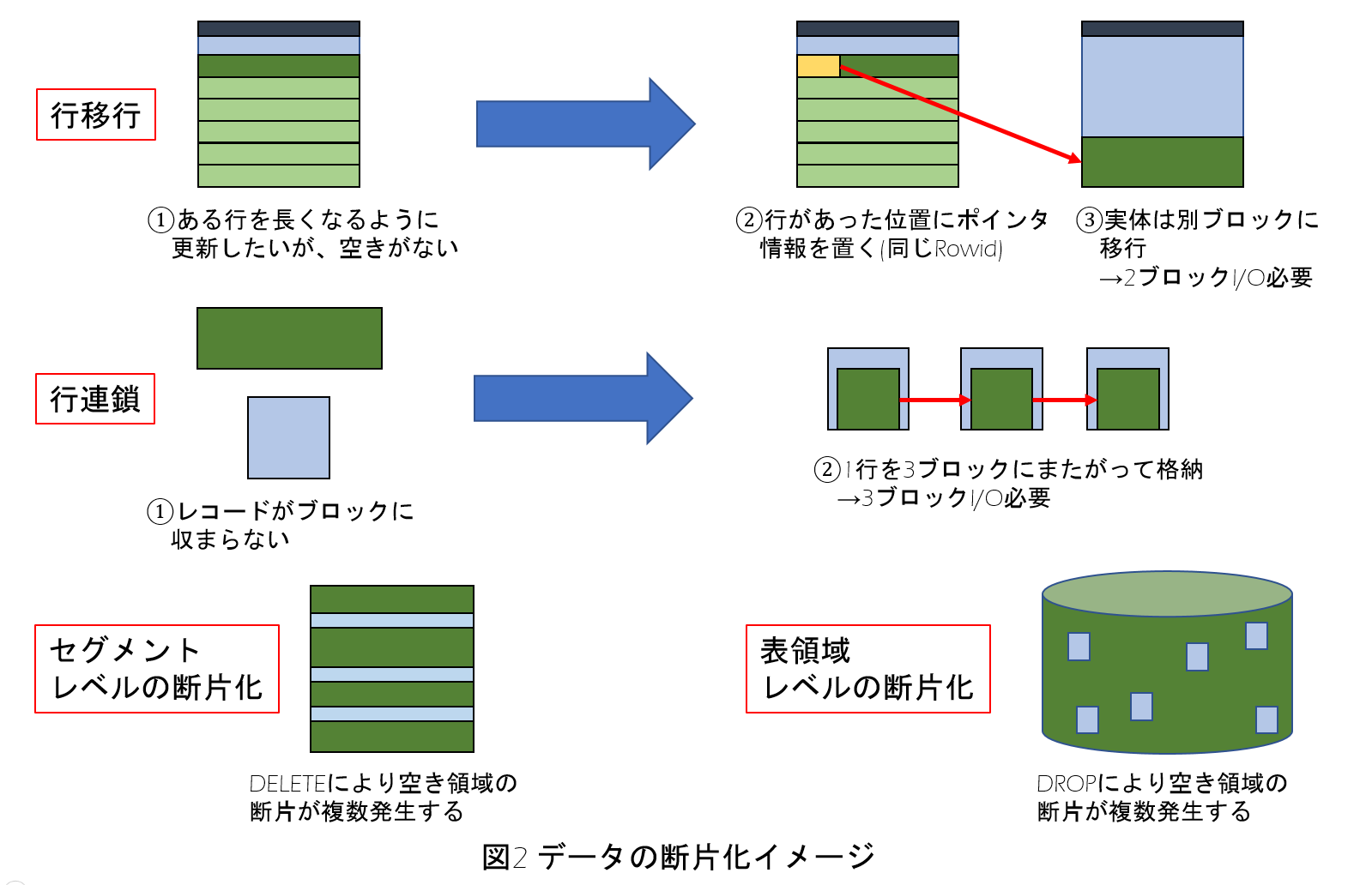
つまり、解消するためのメンテナンスを能動的に実行しない限り断片化は進行し、格納効率および性能面において経年劣化を引き起こす恐れがあります。
一方、SAP HANAのカラムストアでは、そもそもデータブロックに行データを格納するような仕組みがないため、Oracleデータベース等に見られる断片化が発生する余地がありません。
また、連載第2回でご紹介したSAP HANAの中でも非常に重要な機能であるデルタマージにより、メインストレージ内のデータは適切にソート・圧縮が行われるため、読み込み最適なデータ構造が保たれます。
従って、この点においてSAP HANAはローストア型データベースに比べ経年劣化の少ないデータベースとも言えます。
クラスタリングファクタと無縁のインデックス
連載第4回でご紹介したように、SAP HANAにおける(メインストレージの)バリュー配列はインデックスを作成することなくバイナリサーチによる高速な検索が可能です。つまり、ローストア型データベースにおいてすべての列にインデックスを作成するのと同様の効果があります(ただし、バリューID配列にはフル・スキャンを回避するためのインデックスは必要です)。
しかし、ローストア型データベースにおいてテーブルとインデックスは別々のオブジェクトとして存在していますので、すべての列にインデックスを作成したとしてもそれらが最適なインデックスとなる保証はありません。

INDEX RANGE SCANにおいて得られた複数のrowidに対して、実際のテーブルデータが同じブロックに集まっていれば性能が良く、逆に別々のブロックに分散していれば性能が悪くなります。
データ集中分散の度合いを示すクラスタリングファクタ(CF:CLUSTERING FACTOR)はデータの格納状況に依存するので、時系列で増加するキーに対するインデックスのCFは一般的に良く、そうでないインデックスでは悪くなります。 これは、ローイメージでデータが格納されるローストアの宿命であり、あるカラムのCFを改善しようとすれば該当するキー順にデータ全体を格納し直さなければならず、良好だった別カラムのCFが逆に悪化します。
HANAカラムストアの場合、データは各カラム毎独立していますので、バリューID配列検索、あるいは非ユニークキー検索の高速化のために必要なインデックスにはそもそもCFという概念がありません。つまりどのカラムに対しても最適なインデックスを作成することができます。
会員登録無料すると、続きをお読みいただけます
この記事は参考になりましたか?
- Oracle技術者から見た、SAP HANA連載記事一覧
-
- Oracle技術者から見たSAP HANAはここが凄い!
- SAP HANAの永続化技術とは
- HANAはどうやって行を識別しているのか
- この記事の著者
-

三原健一(ミハラケンイチ)
ベンチュリーコンサルティング株式会社 技術顧問 現在、大手SIerの性能問題対応チームに従事。主にOracleデータベースの性能問題解決や負荷テストの計画・実施・分析・評価等を担当。前職のインサイトテクノロジーではメルマガやブログの執筆に関わる。 ・ブログ「サイクル&オラクル」
※プロフィールは、執筆時点、または直近の記事の寄稿時点での内容です

この記事は参考になりましたか?
この記事をシェア